这是本节的多页打印视图。
点击此处打印.
返回本页常规视图.
集群模型图
Pigsty 是如何将不同种类的功能抽象成为模块的,以及这些模块的逻辑模型,实体关系图。
在 Pigsty 中最大的实体概念叫做 部署(Deployment),一套部署中的主要实体与关系(E-R 图)如下所示:

一套部署也可以理解为一个 环境(Environment)。例如,生产环境(Prod),用户测试环境(UTA),预发环境(Staging),测试环境(Testing),开发环境(Devbox),等等。
每个环境中,都对应着一份 Pigsty 配置清单,描述了环境中的所有实体与属性。
通常来说,一套环境中也会带有一套共用的基础设施(INFRA),广义的基础设施还包括 ETCD(高可用 DCS)以及 MINIO(集中式备份仓库),
同时供环境中的多套 PostgreSQL 数据库集群(以及其他数据库模块组件)使用。(例外:也有 不带基础设施的部署)
在 Pigsty 中,几乎所有数据库模块都是以 “集群"(Cluster)的方式组织起来的。每一个集群都是一个 Ansible 分组,包含有若干节点资源。
例如 PostgreSQL 高可用数据库集群,Redis,Etcd / MinIO 这些数据库都是以集群的形式存在。一套环境中可以包含多个集群。
1 - PGSQL 集群模型
介绍 Pigsty 中 PostgreSQL 集群的实体-关系模型,E-R 关系图,实体释义与命名规范。
PGSQL模块在生产环境中以集群的形式组织,这些集群是由一组由主-备关联的数据库实例组成的逻辑实体。
每个集群都是一个自治的业务单元,由至少一个 主库实例 组成,并通过服务向外暴露能力。
在 Pigsty 的PGSQL模块中有四种核心实体:
- 集群(Cluster):自治的 PostgreSQL 业务单元,用作其他实体的顶级命名空间。
- 服务(Service):对外暴露能力的命名抽象,路由流量,并使用节点端口暴露服务。
- 实例(Instance):由在单个节点上的运行进程和数据库文件组成的单一 PostgreSQL 服务器。
- 节点(Node):运行 Linux + Systemd 环境的硬件资源抽象,可以是裸机、VM、容器或 Pod。
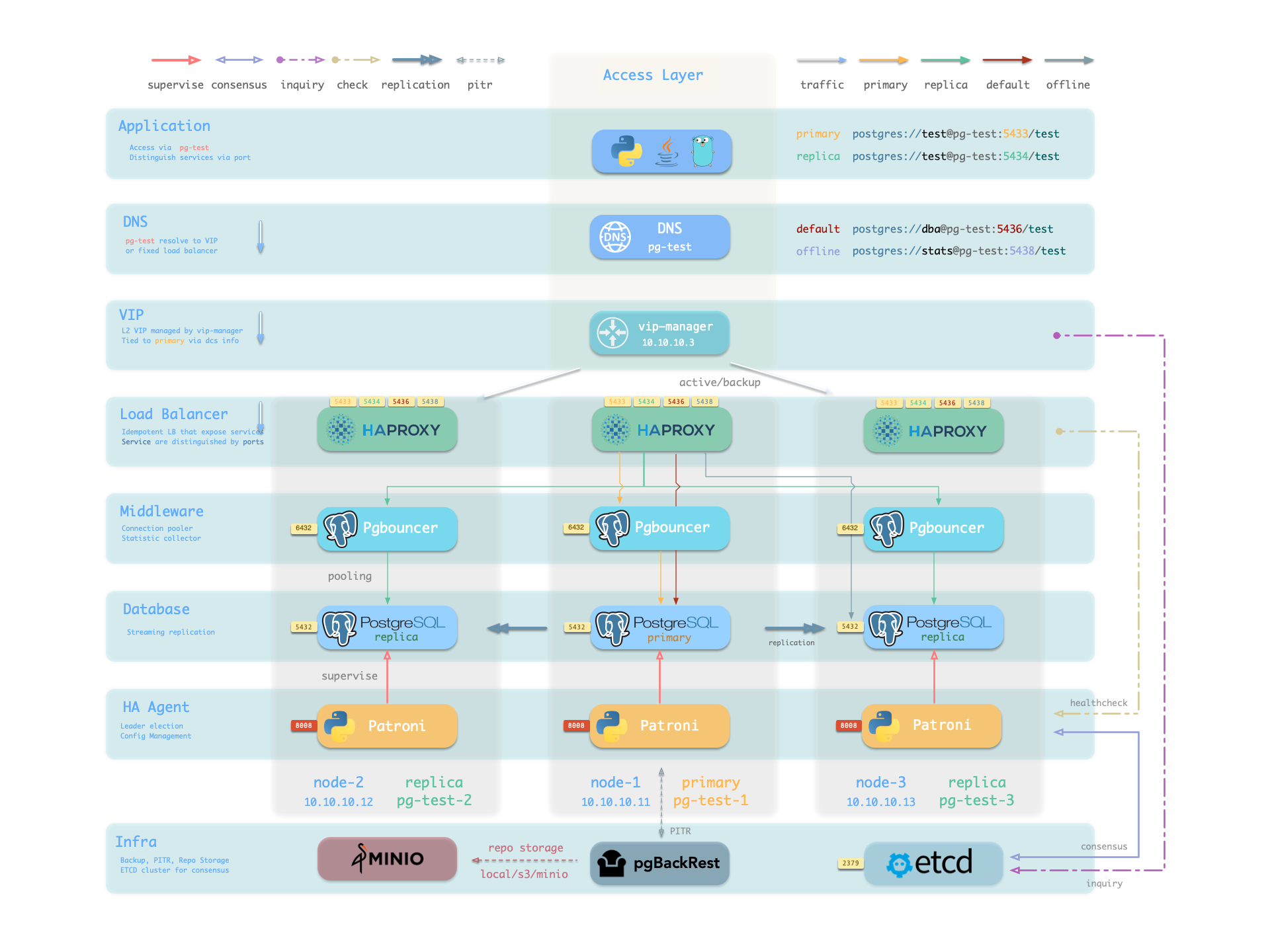
辅以“数据库”“角色”两个业务实体,共同组成完整的逻辑视图。如下图所示:

具体样例
让我们来看两个具体的例子,以四节点的 Pigsty 沙箱环境 为例,在这个环境中,有一套三节点的 pg-test 集群。
pg-test:
hosts:
10.10.10.11: { pg_seq: 1, pg_role: primary }
10.10.10.12: { pg_seq: 2, pg_role: replica }
10.10.10.13: { pg_seq: 3, pg_role: replica }
vars: { pg_cluster: pg-test }
上面的配置片段定义了一个如下所示的 高可用 PostgreSQL 集群,该集群中的相关实体包括:
| 集群 | Cluster |
|---|
pg-test | PostgreSQL 3 节点高可用集群 |
| 实例 | Instance |
pg-test-1 | 1 号 PostgreSQL 实例,默认为主库 |
pg-test-2 | 2 号 PostgreSQL 实例,初始为从库 |
pg-test-3 | 3 号 PostgreSQL 实例,初始为从库 |
| 服务 | Service |
pg-test-primary | 读写服务(路由到主库 pgbouncer) |
pg-test-replica | 只读服务(路由到从库 pgbouncer) |
pg-test-default | 直连读写服务(路由到主库 postgres) |
pg-test-offline | 离线读取服务(路由到专用 postgres) |
| 节点 | Nodes |
node-1 | 10.10.10.11 1 号节点,对应 pg-test-1 PG 实例 |
node-2 | 10.10.10.12 2 号节点,对应 pg-test-2 PG 实例 |
node-3 | 10.10.10.13 3 号节点,对应 pg-test-3 PG 实例 |
身份参数
Pigsty 使用 PG_ID 参数组为 PGSQL 模块的每个实体赋予确定的身份。以下三项为必选参数:
| 参数 | 类型 | 级别 | 说明 | 形式 |
|---|
pg_cluster | string | 集群 | PG 集群名称,必选身份参数 | 有效的 DNS 名称,满足正则表达式 [a-zA-Z0-9-]+ |
pg_seq | int | 实例 | PG 实例编号,必选身份参数 | 自然数,可从 0 或 1 开始分配,集群内不重复 |
pg_role | enum | 实例 | PG 实例角色,必选身份参数 | 枚举值,可为 primary,replica,offline |
只要在集群层面定义了集群名称,实例层面分配了实例编号与角色,Pigsty 就能自动根据规则为每个实体生成唯一标识符。
| 实体 | 生成规则 | 示例 |
|---|
| 实例 | {{ pg_cluster }}-{{ pg_seq }} | pg-test-1,pg-test-2,pg-test-3 |
| 服务 | {{ pg_cluster }}-{{ pg_role }} | pg-test-primary,pg-test-replica,pg-test-offline |
| 节点 | 显示指定覆盖,或自动从 PG 实例借用 | pg-test-1,pg-test-2,pg-test-3 |
因为 Pigsty 采用节点与 PG 实例 1:1 的独占部署模型,因此默认情况下,主机节点的标识符会直接借用 PG 实例的标识符(node_id_from_pg )。
当然您也可以显式指定 nodename 进行覆盖,或者关闭 nodename_overwrite,直接使用当前默认值。
分片身份参数
当你使用多套 PostgreSQL (分片 / Sharding)集群服务同一业务时,还会使用到另外两个身份参数:pg_shard 与 pg_group。
在这种情况下,这一组 PostgreSQL 集群将拥有相同的 pg_shard 名称,以及各自的 pg_group 编号,例如下面的 Citus 集群:
在这种情况下,pg_cluster 集群名通常由:{{ pg_shard }}{{ pg_group }} 组合而成,例如 pg-citus0、pg-citus1 等。
all:
children:
pg-citus0: # citus 0号分片
hosts: { 10.10.10.10: { pg_seq: 1, pg_role: primary } }
vars: { pg_cluster: pg-citus0 , pg_group: 0 }
pg-citus1: # citus 1号分片
hosts: { 10.10.10.11: { pg_seq: 1, pg_role: primary } }
vars: { pg_cluster: pg-citus1 , pg_group: 1 }
pg-citus2: # citus 2号分片
hosts: { 10.10.10.12: { pg_seq: 1, pg_role: primary } }
vars: { pg_cluster: pg-citus2 , pg_group: 2 }
pg-citus3: # citus 3号分片
hosts: { 10.10.10.13: { pg_seq: 1, pg_role: primary } }
vars: { pg_cluster: pg-citus3 , pg_group: 3 }
Pigsty 专门为水平分片集群提供专门的监控面板,便于对比各分片的性能与负载情况,但这需要您使用上述实体命名规则。
还有一些其他的身份参数,可能在特殊场景会使用到,例如,指定备份集群/级联复制上游的 pg_upstream,指定 Greenplum 集群身份的 gp_role ,
指定外部监控实例的 pg_exporters ,指定实例为离线查询库的 pg_offline_query 等,请参考 PG_ID 参数文档。
监控标签体系
Pigsty 提供了一套开箱即用的监控系统,在这个系统中使用上面的 身份参数 来标识各个 PostgreSQL 实体对象。
pg_up{cls="pg-test", ins="pg-test-1", ip="10.10.10.11", job="pgsql"}
pg_up{cls="pg-test", ins="pg-test-2", ip="10.10.10.12", job="pgsql"}
pg_up{cls="pg-test", ins="pg-test-3", ip="10.10.10.13", job="pgsql"}
例如,上面的 cls,ins,ip 三个标签,分别对应集群名、实例名与节点 IP,这三个核心实体的标识符。
它们与 job 标签,在 所有 VictoriaMetrics 采集的原生监控指标,以及 VictoriaLogs 日志流中都会出现并可用。
采集 PostgreSQL 指标的 job 名固定为 pgsql;
用于监控远程 PG 实例的 job 名固定为 pgrds。
采集 PostgreSQL CSV 日志的 job 名固定为 postgres;
采集 pgbackrest 日志的 job 名固定为 pgbackrest,其余 PG 组件通过 job: syslog 采集日志。
此外,还有一些普通实体身份标签,会在实体相关的特定监控指标中出现,例如:
datname: 数据库名,如果一个监控指标属于某个具体的数据库,则会带上这个标签。relname: 表名,如果一个监控指标属于某个具体的表,则会带上这个标签。idxname: 索引名,如果一个监控指标属于某个具体的索引,则会带上这个标签。funcname: 函数名,如果一个监控指标属于某个具体的函数,则会带上这个标签。seqname: 序列名,如果一个监控指标属于某个具体的序列,则会带上这个标签。query: 查询指纹,如果一个监控指标属于某个具体的查询,则会带上这个标签。
2 - ETCD 集群模型
介绍 Pigsty 中 ETCD 集群的实体-关系模型,E-R 关系图,实体释义与命名规范。
ETCD 模块在生产环境中以集群的形式组织,这些集群是由一组通过 Raft 共识协议关联的 ETCD 实例组成的逻辑实体。
每个集群都是一个自治的分布式键值存储单元,由至少一个 ETCD 实例 组成,通过客户端端口向外暴露服务能力。
在 Pigsty 的 ETCD 模块中有三种核心实体:
- 集群(Cluster):自治的 ETCD 服务单元,用作其他实体的顶级命名空间。
- 实例(Instance):单个 ETCD 服务器进程,在节点上运行,参与 Raft 共识。
- 节点(Node):运行 Linux + Systemd 环境的硬件资源抽象,隐含式声明。
相比于 PostgreSQL 集群,ETCD 集群模型更为简单,没有服务(Service)和复杂的角色(Role)区分。
所有 ETCD 实例在功能上是对等的,通过 Raft 协议选举出 Leader,其余为 Follower。
在扩容的中间状态,还允许不参与投票的 Learner 实例成员存在。
具体样例
让我们来看一个具体的例子,以三节点的 ETCD 集群为例:
etcd:
hosts:
10.10.10.10: { etcd_seq: 1 }
10.10.10.11: { etcd_seq: 2 }
10.10.10.12: { etcd_seq: 3 }
vars:
etcd_cluster: etcd
上面的配置片段定义了一个如下所示的三节点 ETCD 集群,该集群中的相关实体包括:
| 集群 | Cluster |
|---|
etcd | ETCD 三节点高可用集群 |
| 实例 | Instance |
etcd-1 | 1 号 ETCD 实例 |
etcd-2 | 2 号 ETCD 实例 |
etcd-3 | 3 号 ETCD 实例 |
| 节点 | Nodes |
10.10.10.10 | 1 号节点,对应 etcd-1 实例 |
10.10.10.11 | 2 号节点,对应 etcd-2 实例 |
10.10.10.12 | 3 号节点,对应 etcd-3 实例 |
身份参数
Pigsty 使用 ETCD 参数组为 ETCD 模块的每个实体赋予确定的身份。以下两项为必选参数:
| 参数 | 类型 | 级别 | 说明 | 形式 |
|---|
etcd_cluster | string | 集群 | ETCD 集群名称,必选身份参数 | 有效的 DNS 名称,默认为固定值 etcd |
etcd_seq | int | 实例 | ETCD 实例编号,必选身份参数 | 自然数,从 1 开始分配,集群内不重复 |
只要在集群层面定义了集群名称,实例层面分配了实例编号,Pigsty 就能自动根据规则为每个实体生成唯一标识符。
| 实体 | 生成规则 | 示例 |
|---|
| 实例 | {{ etcd_cluster }}-{{ etcd_seq }} | etcd-1,etcd-2,etcd-3 |
ETCD 模块不会为主机节点赋予额外的身份标识,节点使用其原有的主机名或 IP 地址进行标识。
端口协议
每个 ETCD 实例会监听以下两个端口:
ETCD 集群默认启用 TLS 加密通信,并使用 RBAC 认证机制。客户端需要使用正确的证书和密码才能访问 ETCD 服务。
集群规模
ETCD 作为分布式协调服务,集群规模直接影响其可用性,需要有超过半数(仲裁数)的节点存活才能维持服务。
| 集群规模 | 仲裁数 | 容忍故障数 | 适用场景 |
|---|
| 1 节点 | 1 | 0 | 开发、测试、演示 |
| 3 节点 | 2 | 1 | 中小规模生产环境 |
| 5 节点 | 3 | 2 | 大规模生产环境 |
因此,偶数节点的 ETCD 集群没有意义,超过五节点的 ETCD 集群并不常见,因此通常使用的规格就是单节点、三节点、五节点。
监控标签体系
Pigsty 提供了一套开箱即用的监控系统,在这个系统中使用上面的 身份参数 来标识各个 ETCD 实体对象。
etcd_up{cls="etcd", ins="etcd-1", ip="10.10.10.10", job="etcd"}
etcd_up{cls="etcd", ins="etcd-2", ip="10.10.10.11", job="etcd"}
etcd_up{cls="etcd", ins="etcd-3", ip="10.10.10.12", job="etcd"}
例如,上面的 cls,ins,ip 三个标签,分别对应集群名、实例名与节点 IP,这三个核心实体的标识符。
它们与 job 标签,在 所有 VictoriaMetrics 采集的 ETCD 监控指标中都会出现并可用。
采集 ETCD 指标的 job 名固定为 etcd。
3 - MINIO 集群模型
介绍 Pigsty 中 MinIO 集群的实体-关系模型,E-R 关系图,实体释义与命名规范。
MinIO 模块在生产环境中以集群的形式组织,这些集群是由一组分布式 MinIO 实例组成的逻辑实体,共同提供高可用的对象存储服务。
每个集群都是一个自治的 S3 兼容对象存储单元,由至少一个 MinIO 实例 组成,通过 S3 API 端口向外暴露服务能力。
在 Pigsty 的 MinIO 模块中有三种核心实体:
- 集群(Cluster):自治的 MinIO 服务单元,用作其他实体的顶级命名空间。
- 实例(Instance):单个 MinIO 服务器进程,在节点上运行,管理本地磁盘存储。
- 节点(Node):运行 Linux + Systemd 环境的硬件资源抽象,隐含式声明。
此外,MinIO 还有 存储池(Pool)的概念,用于集群平滑扩容。
一个集群可以包含多个存储池,每个存储池由一组节点和磁盘组成。
部署模式
MinIO 支持三种主要部署模式,适用于不同的场景:
| 模式 | 代号 | 说明 | 适用场景 |
|---|
| 单机单盘 | SNSD | 单节点,单个数据目录,或单块磁盘 | 开发、测试、演示 |
| 单机多盘 | SNMD | 单节点,使用多块磁盘,通常至少 4 块盘 | 资源受限的小规模部署 |
| 多机多盘 | MNMD | 多节点,每节点多块磁盘 | 生产环境推荐 |
单机单盘模式可以使用任意目录作为存储,适合快速体验;单机多盘和多机多盘模式需要使用真实的磁盘挂载点,否则会拒绝启动。
具体样例
让我们来看一个多机多盘模式的具体例子,以四节点的 MinIO 集群为例:
minio:
hosts:
10.10.10.10: { minio_seq: 1 }
10.10.10.11: { minio_seq: 2 }
10.10.10.12: { minio_seq: 3 }
10.10.10.13: { minio_seq: 4 }
vars:
minio_cluster: minio
minio_data: '/data{1...4}'
minio_node: '${minio_cluster}-${minio_seq}.pigsty'
上面的配置片段定义了一个四节点的 MinIO 集群,每个节点使用四块磁盘,该集群中的相关实体包括:
| 集群 | Cluster |
|---|
minio | MinIO 四节点高可用集群 |
| 实例 | Instance |
minio-1 | 1 号 MinIO 实例,管理 4 块磁盘 |
minio-2 | 2 号 MinIO 实例,管理 4 块磁盘 |
minio-3 | 3 号 MinIO 实例,管理 4 块磁盘 |
minio-4 | 4 号 MinIO 实例,管理 4 块磁盘 |
| 节点 | Nodes |
10.10.10.10 | 1 号节点,对应 minio-1 实例 |
10.10.10.11 | 2 号节点,对应 minio-2 实例 |
10.10.10.12 | 3 号节点,对应 minio-3 实例 |
10.10.10.13 | 4 号节点,对应 minio-4 实例 |
身份参数
Pigsty 使用 MINIO 参数组为 MinIO 模块的每个实体赋予确定的身份。以下两项为必选参数:
| 参数 | 类型 | 级别 | 说明 | 形式 |
|---|
minio_cluster | string | 集群 | MinIO 集群名称,必选身份参数 | 有效的 DNS 名称,默认为 minio |
minio_seq | int | 实例 | MinIO 实例编号,必选身份参数 | 自然数,从 1 开始分配,集群内不重复 |
只要在集群层面定义了集群名称,实例层面分配了实例编号,Pigsty 就能自动根据规则为每个实体生成唯一标识符。
| 实体 | 生成规则 | 示例 |
|---|
| 实例 | {{ minio_cluster }}-{{ minio_seq }} | minio-1,minio-2,minio-3,minio-4 |
MinIO 模块不会为主机节点赋予额外的身份标识,节点使用其原有的主机名或 IP 地址进行标识。
minio_node 参数用于生成 MinIO 集群内部的节点名称(写入 /etc/hosts 供集群发现使用),而非主机节点的身份。
核心配置参数
除身份参数外,以下参数对 MinIO 集群配置至关重要:
这些参数共同决定了 MinIO 的核心配置 MINIO_VOLUMES:
- 单机单盘:直接使用
minio_data 的值,如 /data/minio - 单机多盘:使用
minio_data 展开的多个目录,如 /data{1...4} - 多机多盘:组合
minio_node 与 minio_data,如 https://minio-{1...4}.pigsty:9000/data{1...4}
端口与服务
每个 MinIO 实例会监听以下端口:
MinIO 默认启用 HTTPS 加密通信(由 minio_https 控制)。这对于 pgBackREST 等备份工具访问 MinIO 是必需的。
多节点 MinIO 集群可以通过访问 任意一个节点 来访问其服务。最佳实践是使用负载均衡器(如 HAProxy + VIP)统一接入点。
资源置备
MinIO 集群部署后,Pigsty 会自动创建以下资源(由 minio_provision 控制):
默认存储桶(由 minio_buckets 定义):
| 存储桶 | 用途 |
|---|
pgsql | PostgreSQL pgBackREST 备份存储 |
meta | 元数据存储,启用版本控制 |
data | 通用数据存储 |
默认用户(由 minio_users 定义):
| 用户 | 默认密码 | 策略 | 用途 |
|---|
pgbackrest | S3User.Backup | pgsql | PostgreSQL 备份专用用户 |
s3user_meta | S3User.Meta | meta | 访问 meta 存储桶 |
s3user_data | S3User.Data | data | 访问 data 存储桶 |
pgbackrest 是 PostgreSQL 集群备份时使用的用户,s3user_meta 和 s3user_data 是未实际使用的保留用户。
监控标签体系
Pigsty 提供了一套开箱即用的监控系统,在这个系统中使用上面的 身份参数 来标识各个 MinIO 实体对象。
minio_up{cls="minio", ins="minio-1", ip="10.10.10.10", job="minio"}
minio_up{cls="minio", ins="minio-2", ip="10.10.10.11", job="minio"}
minio_up{cls="minio", ins="minio-3", ip="10.10.10.12", job="minio"}
minio_up{cls="minio", ins="minio-4", ip="10.10.10.13", job="minio"}
例如,上面的 cls,ins,ip 三个标签,分别对应集群名、实例名与节点 IP,这三个核心实体的标识符。
它们与 job 标签,在 所有 VictoriaMetrics 采集的 MinIO 监控指标中都会出现并可用。
采集 MinIO 指标的 job 名固定为 minio。
4 - REDIS 集群模型
介绍 Pigsty 中 Redis 集群的实体-关系模型,E-R 关系图,实体释义与命名规范。
Redis 模块在生产环境中以集群的形式组织,这些集群是由一组 Redis 实例组成的逻辑实体,部署在一个或多个节点上。
每个集群都是一个自治的高性能缓存/存储单元,由至少一个 Redis 实例 组成,通过端口向外暴露服务能力。
在 Pigsty 的 Redis 模块中有三种核心实体:
- 集群(Cluster):自治的 Redis 服务单元,用作其他实体的顶级命名空间。
- 实例(Instance):单个 Redis 服务器进程,在节点上的特定端口运行。
- 节点(Node):运行 Linux + Systemd 环境的硬件资源抽象,可以承载多个 Redis 实例,隐含式声明。
与 PostgreSQL 不同,Redis 采用 单机多实例 的部署模型:一个物理/虚拟机节点上通常会部署 多个 Redis 实例,
以充分利用多核 CPU。因此,节点与实例是 1:N 的关系。此外,生产中通常不建议设置单个内存规模大于 12GB 的 Redis 实例。
工作模式
Redis 有三种不同的工作模式,由 redis_mode 参数指定:
| 模式 | 代号 | 说明 | 高可用机制 |
|---|
| 主从模式 | standalone | 经典主从复制,默认模式 | 需配合 Sentinel 实现 |
| 哨兵模式 | sentinel | 为主从模式提供高可用监控与自动故障转移 | 本身的多节点仲裁 |
| 原生集群模式 | cluster | Redis 原生分布式集群,无需哨兵即可高可用 | 内置自动故障转移 |
- 主从模式:默认模式,通过
replica_of 参数设置主从复制关系。需要额外的 Sentinel 集群提供高可用。 - 哨兵模式:不存储业务数据,专门用于监控主从模式的 Redis 集群,实现自动故障转移,本身多节点即可高可用。
- 原生集群模式:数据自动分片到多个主节点,每个主节点可以有多个从节点,内置高可用能力,无需哨兵支持。
具体样例
让我们来看三种模式的具体例子:
主从集群
一个节点上部署一主一从的经典主从集群:
redis-ms:
hosts:
10.10.10.10:
redis_node: 1
redis_instances:
6379: { }
6380: { replica_of: '10.10.10.10 6379' }
vars:
redis_cluster: redis-ms
redis_password: 'redis.ms'
redis_max_memory: 64MB
| 集群 | Cluster |
|---|
redis-ms | Redis 主从集群 |
| 节点 | Nodes |
redis-ms-1 | 10.10.10.10 1 号节点,承载 2 个实例 |
| 实例 | Instance |
redis-ms-1-6379 | 主库实例,监听 6379 端口 |
redis-ms-1-6380 | 从库实例,监听 6380 端口,复制自 6379 |
哨兵集群
一个节点上部署三个哨兵实例,用于监控主从集群。哨兵集群通过 redis_sentinel_monitor 参数指定要监控的主从集群列表:
redis-sentinel:
hosts:
10.10.10.11:
redis_node: 1
redis_instances: { 26379: {}, 26380: {}, 26381: {} }
vars:
redis_cluster: redis-sentinel
redis_password: 'redis.sentinel'
redis_mode: sentinel
redis_max_memory: 16MB
redis_sentinel_monitor:
- { name: redis-ms, host: 10.10.10.10, port: 6379, password: redis.ms, quorum: 2 }
原生集群
下面的配置片段定义了由两个节点,六个实例组成的 Redis 原生分布式集群(最小规格,3主3从):
redis-test:
hosts:
10.10.10.12: { redis_node: 1, redis_instances: { 6379: {}, 6380: {}, 6381: {} } }
10.10.10.13: { redis_node: 2, redis_instances: { 6379: {}, 6380: {}, 6381: {} } }
vars:
redis_cluster: redis-test
redis_password: 'redis.test'
redis_mode: cluster
redis_max_memory: 32MB
该配置将创建一个 3 主 3 从 的原生 Redis 集群。
| 集群 | Cluster |
|---|
redis-test | Redis 原生集群(3 主 3 从) |
| 实例 | Instance |
redis-test-1-6379 | 节点 1 上的实例,监听 6379 端口 |
redis-test-1-6380 | 节点 1 上的实例,监听 6380 端口 |
redis-test-1-6381 | 节点 1 上的实例,监听 6381 端口 |
redis-test-2-6379 | 节点 2 上的实例,监听 6379 端口 |
redis-test-2-6380 | 节点 2 上的实例,监听 6380 端口 |
redis-test-2-6381 | 节点 2 上的实例,监听 6381 端口 |
| 节点 | Nodes |
redis-test-1 | 10.10.10.12 1 号节点,承载 3 个实例 |
redis-test-2 | 10.10.10.13 2 号节点,承载 3 个实例 |
身份参数
Pigsty 使用 REDIS 参数组为 Redis 模块的每个实体赋予确定的身份。以下三项为必选参数:
| 参数 | 类型 | 级别 | 说明 | 形式 |
|---|
redis_cluster | string | 集群 | Redis 集群名称,必选身份参数 | 有效的 DNS 名称,满足 [a-z][a-z0-9-]* |
redis_node | int | 节点 | Redis 节点编号,必选身份参数 | 自然数,从 1 开始分配,集群内不重复 |
redis_instances | dict | 节点 | Redis 实例定义,必选身份参数 | JSON 对象,Key 为端口号,Value 为实例配置 |
只要在集群层面定义了集群名称,节点层面分配了节点编号与实例定义,Pigsty 就能自动根据规则为每个实体生成唯一标识符。
| 实体 | 生成规则 | 示例 |
|---|
| 实例 | {{ redis_cluster }}-{{ redis_node }}-{{ port }} | redis-ms-1-6379,redis-ms-1-6380 |
Redis 模块不会为主机节点赋予额外的身份标识,节点使用其原有的主机名或 IP 地址进行标识。
redis_node 参数用于实例命名,而非主机节点的身份。
实例定义
redis_instances 是一个 JSON 对象,Key 为 端口号,Value 为该实例的 配置项:
redis_instances:
6379: { } # 主库实例,无需额外配置
6380: { replica_of: '10.10.10.10 6379' } # 从库实例,指定上游主库
6381: { replica_of: '10.10.10.10 6379' } # 从库实例,指定上游主库
每个 Redis 实例会监听一个唯一的端口,端口在节点上唯一不重复,您可以任意选择端口号,
但请不要使用系统保留端口(小于 1024),或者与 Pigsty 使用的端口 冲突。
实例配置中的 replica_of 参数用于在主从模式下设置复制关系,格式为 '<ip> <port>',用于指定一个 Redis 从库的上游主库地址与端口。
此外,每个 Redis 节点上会运行一个 Redis Exporter,用于汇总采集当前节点上 所有本地实例 的监控指标:
Redis 模块的单机多实例部署模型带有一些一些局限性:
- 节点独占:一个节点只能属于一个 Redis 集群,不能同时分配给不同的 Redis 集群。
- 端口唯一:同一节点上的 Redis 实例必须使用不同的端口号,避免端口冲突。
- 密码共享:同一节点上的多个 Redis 实例无法设置不同的密码(受 redis_exporter 限制)。
- 手动高可用:主从模式的 Redis 集群需要额外配置 Sentinel 才能实现自动故障转移。
监控标签体系
Pigsty 提供了一套开箱即用的监控系统,在这个系统中使用上面的 身份参数 来标识各个 Redis 实体对象。
redis_up{cls="redis-ms", ins="redis-ms-1-6379", ip="10.10.10.10", job="redis"}
redis_up{cls="redis-ms", ins="redis-ms-1-6380", ip="10.10.10.10", job="redis"}
例如,上面的 cls,ins,ip 三个标签,分别对应集群名、实例名与节点 IP,这三个核心实体的标识符。
它们与 job 标签,在 所有 VictoriaMetrics 采集的 Redis 监控指标中都会出现并可用。
采集 Redis 指标的 job 名固定为 redis。
5 - INFRA 集群模型
介绍 Pigsty 中 INFRA 基础设施节点的实体-关系模型,组件构成与命名规范。
INFRA 模块在 Pigsty 中承担着特殊的角色:它不是传统意义上的"集群",而是由一组 基础设施节点 构成的管理中枢,为整个 Pigsty 部署提供核心服务。
每个 INFRA 节点都是一个自治的基础设施服务单元,运行着 Nginx、Grafana、VictoriaMetrics 等核心组件,共同为纳管的数据库集群提供可观测性与管理能力。
在 Pigsty 的 INFRA 模块中有两种核心实体:
- 节点(Node):运行基础设施组件的服务器,可以是裸机、VM、容器或 Pod。
- 组件(Component):在节点上运行的各类基础设施服务,如 Nginx、Grafana、VictoriaMetrics 等。
INFRA 节点通常承担管理节点(Admin Node)的角色,是 Pigsty 的控制平面所在。
组件构成
每个 INFRA 节点上运行着以下核心组件:
这些组件共同构成了 Pigsty 的可观测性基础设施。
具体样例
让我们来看一个具体的例子,以双节点的 INFRA 部署为例:
infra:
hosts:
10.10.10.10: { infra_seq: 1 }
10.10.10.11: { infra_seq: 2 }
上面的配置片段定义了一个双节点的 INFRA 部署:
| 分组 | Group |
|---|
infra | INFRA 基础设施节点分组 |
| 节点 | Nodes |
infra-1 | 10.10.10.10 1 号 INFRA 节点 |
infra-2 | 10.10.10.11 2 号 INFRA 节点 |
在生产环境中,建议部署至少两个 INFRA 节点,以实现基础设施组件的冗余。
身份参数
Pigsty 使用 INFRA_ID 参数组为 INFRA 模块的每个实体赋予确定的身份。以下一项为必选参数:
| 参数 | 类型 | 级别 | 说明 | 形式 |
|---|
infra_seq | int | 节点 | INFRA 节点序号,必选身份参数 | 自然数,从 1 开始分配,分组内不重复 |
只要在节点层面分配了节点序号,Pigsty 就能自动根据规则为每个实体生成唯一标识符。
| 实体 | 生成规则 | 示例 |
|---|
| 节点 | infra-{{ infra_seq }} | infra-1,infra-2 |
INFRA 模块会为节点赋予 infra-N 形式的标识,用于监控系统中区分多个基础设施节点。
但这并不改变节点本身的主机名或系统身份,节点仍然使用其原有的主机名或 IP 地址进行标识。
服务门户
INFRA 节点通过 Nginx 提供统一的 Web 服务入口。infra_portal 参数定义了通过 Nginx 暴露的服务列表。
默认配置只定义了首页服务器:
infra_portal:
home : { domain: i.pigsty }
Pigsty 会自动为启用的组件(如 Grafana、VictoriaMetrics、AlertManager 等)配置反向代理端点。如果需要通过独立域名访问这些服务,可以显式添加配置:
infra_portal:
home : { domain: i.pigsty }
grafana : { domain: g.pigsty, endpoint: "${admin_ip}:3000", websocket: true }
prometheus : { domain: p.pigsty, endpoint: "${admin_ip}:8428" } # VMUI
alertmanager : { domain: a.pigsty, endpoint: "${admin_ip}:9059" }
| 域名 | 服务 | 说明 |
|---|
i.pigsty | Home | Pigsty 首页 |
g.pigsty | Grafana | 监控可视化平台 |
p.pigsty | VictoriaMetrics | 时序数据库 Web UI |
a.pigsty | Alertmanager | 告警管理界面 |
建议通过域名访问 Pigsty 服务,而不是直接使用 IP + 端口的方式。
部署规模
INFRA 节点的数量取决于部署规模和高可用需求:
| 部署规模 | INFRA 节点数 | 说明 |
|---|
| 开发测试 | 1 | 单节点部署,所有组件在同一节点 |
| 小规模生产 | 1-2 | 单节点或双节点,可与其他服务共用节点 |
| 中规模生产 | 2-3 | 独立的 INFRA 节点,组件冗余部署 |
| 大规模生产 | 3+ | 多 INFRA 节点,可根据组件分离部署 |
单机部署 时,INFRA 组件与 PGSQL、ETCD 等模块共用同一个节点。
通常在小规模部署中,INFRA 节点通常还承担着 “管理节点” / “备用管理节点”,以及本地软件仓库(/www/pigsty)的角色。
在更大规模的部署中,这些职责可以剥离至专用节点。
监控标签体系
Pigsty 的监控系统会采集 INFRA 组件自身的指标。与数据库模块不同,INFRA 模块的每个组件都被视为独立的监控对象,通过 cls(类)标签区分不同组件类型。
| 标签 | 说明 | 示例 |
|---|
cls | 组件类型,每种组件各自构成一个"类" | nginx |
ins | 实例名,格式为 {组件类型}-{infra_seq} | nginx-1 |
ip | 运行该组件的 INFRA 节点 IP 地址 | 10.10.10.10 |
job | VictoriaMetrics 采集任务名,固定为 infra | infra |
以双节点 INFRA 部署(infra_seq: 1 和 infra_seq: 2)为例,各组件的监控标签如下:
| 组件 | cls | ins 示例 | 端口 |
|---|
| Nginx | nginx | nginx-1,nginx-2 | 9113 |
| Grafana | grafana | grafana-1,grafana-2 | 3000 |
| VictoriaMetrics | vmetrics | vmetrics-1,vmetrics-2 | 8428 |
| VictoriaLogs | vlogs | vlogs-1,vlogs-2 | 9428 |
| VictoriaTraces | vtraces | vtraces-1,vtraces-2 | 10428 |
| VMAlert | vmalert | vmalert-1,vmalert-2 | 8880 |
| Alertmanager | alertmanager | alertmanager-1,alertmanager-2 | 9059 |
| Blackbox | blackbox | blackbox-1,blackbox-2 | 9115 |
所有 INFRA 组件的监控指标都使用统一的 job="infra" 标签,通过 cls 标签区分组件类型:
nginx_up{cls="nginx", ins="nginx-1", ip="10.10.10.10", job="infra"}
grafana_info{cls="grafana", ins="grafana-1", ip="10.10.10.10", job="infra"}
vm_app_version{cls="vmetrics", ins="vmetrics-1", ip="10.10.10.10", job="infra"}
vlogs_rows_ingested_total{cls="vlogs", ins="vlogs-1", ip="10.10.10.10", job="infra"}
alertmanager_alerts{cls="alertmanager", ins="alertmanager-1", ip="10.10.10.10", job="infra"}