PGSQL 集群模型
PGSQL模块在生产环境中以集群的形式组织,这些集群是由一组由主-备关联的数据库实例组成的逻辑实体。
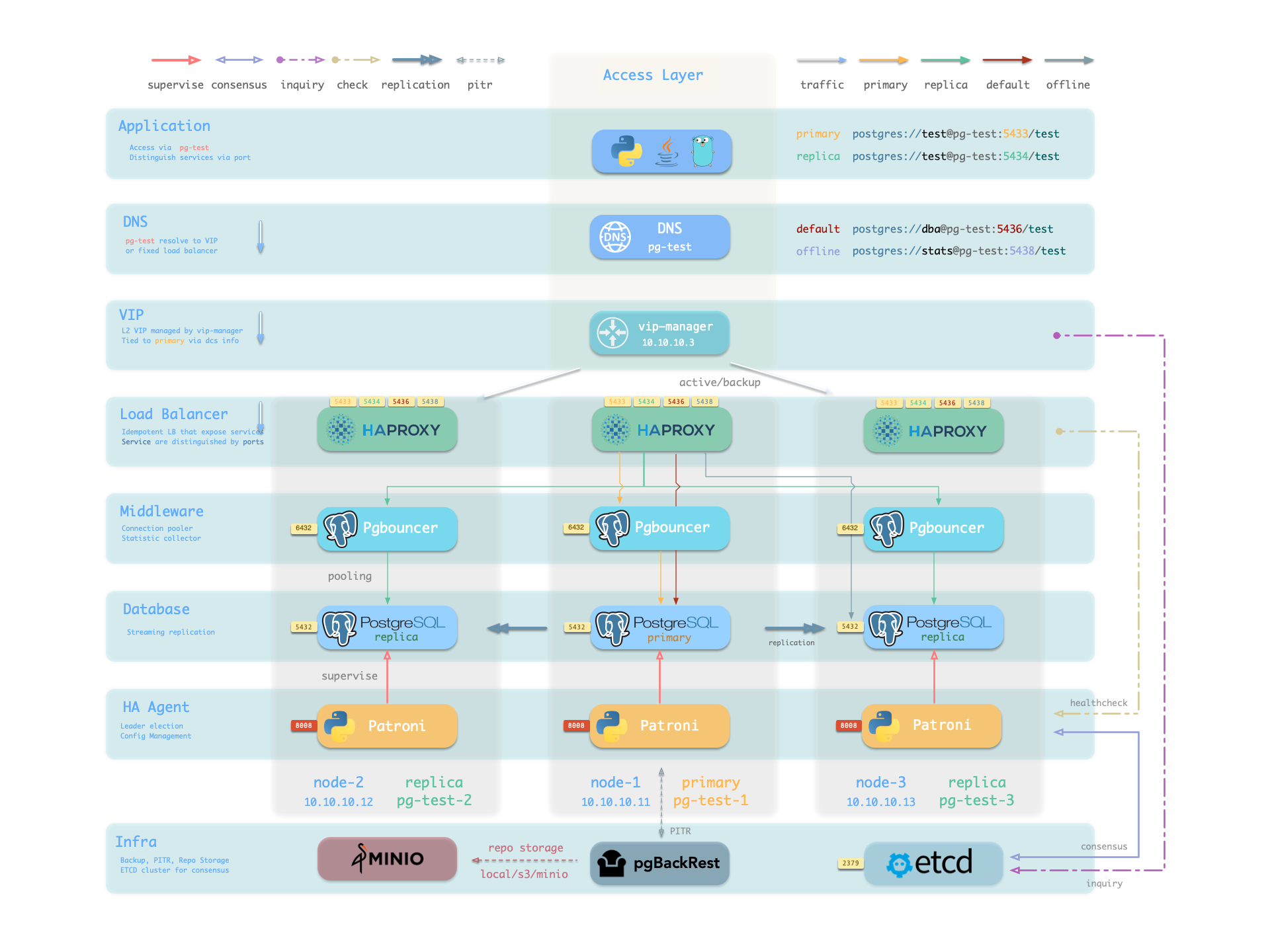
每个集群都是一个自治的业务单元,由至少一个 主库实例 组成,并通过服务向外暴露能力。
在 Pigsty 的PGSQL模块中有四种核心实体:
- 集群(Cluster):自治的 PostgreSQL 业务单元,用作其他实体的顶级命名空间。
- 服务(Service):对外暴露能力的命名抽象,路由流量,并使用节点端口暴露服务。
- 实例(Instance):由在单个节点上的运行进程和数据库文件组成的单一 PostgreSQL 服务器。
- 节点(Node):运行 Linux + Systemd 环境的硬件资源抽象,可以是裸机、VM、容器或 Pod。
辅以“数据库”“角色”两个业务实体,共同组成完整的逻辑视图。如下图所示:

具体样例
让我们来看两个具体的例子,以四节点的 Pigsty 沙箱环境 为例,在这个环境中,有一套三节点的 pg-test 集群。
pg-test:
hosts:
10.10.10.11: { pg_seq: 1, pg_role: primary }
10.10.10.12: { pg_seq: 2, pg_role: replica }
10.10.10.13: { pg_seq: 3, pg_role: replica }
vars: { pg_cluster: pg-test }
上面的配置片段定义了一个如下所示的 高可用 PostgreSQL 集群,该集群中的相关实体包括:
| 集群 | Cluster |
|---|---|
pg-test | PostgreSQL 3 节点高可用集群 |
| 实例 | Instance |
pg-test-1 | 1 号 PostgreSQL 实例,默认为主库 |
pg-test-2 | 2 号 PostgreSQL 实例,初始为从库 |
pg-test-3 | 3 号 PostgreSQL 实例,初始为从库 |
| 服务 | Service |
pg-test-primary | 读写服务(路由到主库 pgbouncer) |
pg-test-replica | 只读服务(路由到从库 pgbouncer) |
pg-test-default | 直连读写服务(路由到主库 postgres) |
pg-test-offline | 离线读取服务(路由到专用 postgres) |
| 节点 | Nodes |
node-1 | 10.10.10.11 1 号节点,对应 pg-test-1 PG 实例 |
node-2 | 10.10.10.12 2 号节点,对应 pg-test-2 PG 实例 |
node-3 | 10.10.10.13 3 号节点,对应 pg-test-3 PG 实例 |
身份参数
Pigsty 使用 PG_ID 参数组为 PGSQL 模块的每个实体赋予确定的身份。以下三项为必选参数:
| 参数 | 类型 | 级别 | 说明 | 形式 |
|---|---|---|---|---|
pg_cluster | string | 集群 | PG 集群名称,必选身份参数 | 有效的 DNS 名称,满足正则表达式 [a-zA-Z0-9-]+ |
pg_seq | int | 实例 | PG 实例编号,必选身份参数 | 自然数,可从 0 或 1 开始分配,集群内不重复 |
pg_role | enum | 实例 | PG 实例角色,必选身份参数 | 枚举值,可为 primary,replica,offline |
只要在集群层面定义了集群名称,实例层面分配了实例编号与角色,Pigsty 就能自动根据规则为每个实体生成唯一标识符。
| 实体 | 生成规则 | 示例 |
|---|---|---|
| 实例 | {{ pg_cluster }}-{{ pg_seq }} | pg-test-1,pg-test-2,pg-test-3 |
| 服务 | {{ pg_cluster }}-{{ pg_role }} | pg-test-primary,pg-test-replica,pg-test-offline |
| 节点 | 显示指定覆盖,或自动从 PG 实例借用 | pg-test-1,pg-test-2,pg-test-3 |
因为 Pigsty 采用节点与 PG 实例 1:1 的独占部署模型,因此默认情况下,主机节点的标识符会直接借用 PG 实例的标识符(node_id_from_pg )。
当然您也可以显式指定 nodename 进行覆盖,或者关闭 nodename_overwrite,直接使用当前默认值。
分片身份参数
当你使用多套 PostgreSQL (分片 / Sharding)集群服务同一业务时,还会使用到另外两个身份参数:pg_shard 与 pg_group。
在这种情况下,这一组 PostgreSQL 集群将拥有相同的 pg_shard 名称,以及各自的 pg_group 编号,例如下面的 Citus 集群:
在这种情况下,pg_cluster 集群名通常由:{{ pg_shard }}{{ pg_group }} 组合而成,例如 pg-citus0、pg-citus1 等。
all:
children:
pg-citus0: # citus 0号分片
hosts: { 10.10.10.10: { pg_seq: 1, pg_role: primary } }
vars: { pg_cluster: pg-citus0 , pg_group: 0 }
pg-citus1: # citus 1号分片
hosts: { 10.10.10.11: { pg_seq: 1, pg_role: primary } }
vars: { pg_cluster: pg-citus1 , pg_group: 1 }
pg-citus2: # citus 2号分片
hosts: { 10.10.10.12: { pg_seq: 1, pg_role: primary } }
vars: { pg_cluster: pg-citus2 , pg_group: 2 }
pg-citus3: # citus 3号分片
hosts: { 10.10.10.13: { pg_seq: 1, pg_role: primary } }
vars: { pg_cluster: pg-citus3 , pg_group: 3 }
Pigsty 专门为水平分片集群提供专门的监控面板,便于对比各分片的性能与负载情况,但这需要您使用上述实体命名规则。
还有一些其他的身份参数,可能在特殊场景会使用到,例如,指定备份集群/级联复制上游的 pg_upstream,指定 Greenplum 集群身份的 gp_role ,
指定外部监控实例的 pg_exporters ,指定实例为离线查询库的 pg_offline_query 等,请参考 PG_ID 参数文档。
监控标签体系
Pigsty 提供了一套开箱即用的监控系统,在这个系统中使用上面的 身份参数 来标识各个 PostgreSQL 实体对象。
pg_up{cls="pg-test", ins="pg-test-1", ip="10.10.10.11", job="pgsql"}
pg_up{cls="pg-test", ins="pg-test-2", ip="10.10.10.12", job="pgsql"}
pg_up{cls="pg-test", ins="pg-test-3", ip="10.10.10.13", job="pgsql"}
例如,上面的 cls,ins,ip 三个标签,分别对应集群名、实例名与节点 IP,这三个核心实体的标识符。
它们与 job 标签,在 所有 VictoriaMetrics 采集的原生监控指标,以及 VictoriaLogs 日志流中都会出现并可用。
采集 PostgreSQL 指标的 job 名固定为 pgsql;
用于监控远程 PG 实例的 job 名固定为 pgrds。
采集 PostgreSQL CSV 日志的 job 名固定为 postgres;
采集 pgbackrest 日志的 job 名固定为 pgbackrest,其余 PG 组件通过 job: syslog 采集日志。
此外,还有一些普通实体身份标签,会在实体相关的特定监控指标中出现,例如:
datname: 数据库名,如果一个监控指标属于某个具体的数据库,则会带上这个标签。relname: 表名,如果一个监控指标属于某个具体的表,则会带上这个标签。idxname: 索引名,如果一个监控指标属于某个具体的索引,则会带上这个标签。funcname: 函数名,如果一个监控指标属于某个具体的函数,则会带上这个标签。seqname: 序列名,如果一个监控指标属于某个具体的序列,则会带上这个标签。query: 查询指纹,如果一个监控指标属于某个具体的查询,则会带上这个标签。