这是本节的多页打印视图。
点击此处打印.
返回本页常规视图.
时间点恢复
Pigsty 使用 pgBackRest 实现了 PostgreSQL 时间点恢复,允许用户回滚至备份策略容许范围内的任意时间点。
当您不小心删除了数据、表、甚至整个数据库时,PITR 能力让您回到过去任意时刻,避免软件缺陷与人为失误导致的数据损失。
—— 这个曾经只有资深 DBA 才能施展的『魔法』,现在对所有用户都可以轻松做到零配置开箱即用。
概览
Pigsty 的 PostgreSQL 集群带有自动配置的时间点恢复(PITR)方案,基于 pgBackRest 与可选的对象存储仓库 MinIO 提供。
高可用方案 可以解决硬件故障,但却对软件缺陷与人为失误导致的数据删除/覆盖写入/删库等问题却无能为力。
对于这种情况,Pigsty 提供了开箱即用的 时间点恢复(Point in Time Recovery, PITR)能力,无需额外配置即默认启用。
Pigsty 为您提供了基础备份与 WAL 归档的默认配置,您可以使用本地目录与磁盘,亦或专用的 MinIO 集群或 S3 对象存储服务来存储备份并实现异地容灾。
当您使用本地磁盘时,默认保留恢复至过去一天内的任意时间点的能力。当您使用 MinIO 或 S3 时,默认保留恢复至过去一周内的任意时间点的能力。
只要存储空间管够,您尽可保留任意长地可恢复时间段,丰俭由人。
时间点恢复解决什么问题?
- 容灾能⼒增强:RPO 从 ∞ 降⾄ ⼗⼏MB, RTO 从 ∞ 降⾄ ⼏⼩时/⼏刻钟。
- 确保数据安全:C/I/A 中的 数据完整性:避免误删导致的数据⼀致性问题。
- 确保数据安全:C/I/A 中的 数据可⽤性:提供对“永久不可⽤”这种灾难情况的兜底
| 单实例配置策略 | 事件 | RTO | RPO |
|---|
| 什么也不做 | 宕机 | 永久丢失 | 全部丢失 |
| 基础备份 | 宕机 | 取决于备份大小与带宽(几小时) | 丢失上一次备份后的数据(几个小时到几天) |
| 基础备份 + WAL归档 | 宕机 | 取决于备份大小与带宽(几小时) | 丢失最后尚未归档的数据(几十MB) |
时间点恢复有什么代价?
- 降低数据安全中的 C:机密性,产生额外泄漏点,需要额外对备份进⾏保护。
- 额外的资源消耗:本地存储或⽹络流量 / 带宽开销,通常并不是⼀个问题。
- 复杂度代价升⾼:⽤户需要付出备份管理成本。
时间点恢复的局限性
如果只有 PITR 用于故障恢复,则 RTO 与 RPO 指标相比 高可用方案 更为逊色,通常应两者组合使用。
- RTO:如果只有单机 + PITR,恢复时长取决于备份大小与网络/磁盘带宽,从十几分钟到几小时,几天不等。
- RPO:如果只有单机 + PITR,宕机时可能丢失少量数据,一个或几个 WAL 日志段文件可能尚未归档,损失 16 MB 到⼏⼗ MB 不等的数据。
除了 PITR 之外,您还可以在 Pigsty 中使用 延迟集群 来解决人为失误或软件缺陷导致的数据误删误改问题。
原理
时间点恢复允许您将集群恢复回滚至过去的“任意时刻”,避免软件缺陷与人为失误导致的数据损失。要做到这一点,首先需要做好两样准备工作:基础备份 与 WAL归档。
拥有 基础备份,允许用户将数据库恢复至备份时的状态,而同时拥有从某个基础备份开始的 WAL归档,允许用户将数据库恢复至基础备份时刻之后的任意时间点。
详细原理,请参阅:基础备份与时间点恢复;具体操作,请参考 PGSQL管理:备份恢复。
基础备份
Pigsty 使用 pgbackrest 管理 PostgreSQL 备份。pgBackRest 将在所有集群实例上初始化空仓库,但只会在集群主库上实际使用仓库。
pgBackRest 支持三种备份模式:全量备份,增量备份,差异备份,其中前两者最为常用。
全量备份将对数据库集群取一个当前时刻的全量物理快照,增量备份会记录当前数据库集群与上一次全量备份之间的差异。
Pigsty 为备份提供了封装命令:/pg/bin/pg-backup [full|incr]。您可以通过 Crontab 或任何其他任务调度系统,按需定期制作基础备份。
WAL归档
Pigsty 默认在集群主库上启⽤了 WAL 归档,并使⽤ pgbackrest 命令行工具持续推送 WAL 段⽂件至备份仓库。
pgBackRest 会⾃动管理所需的 WAL ⽂件,并根据备份的保留策略及时清理过期的备份,与其对应的 WAL 归档⽂件。
如果您不需要 PITR 功能,可以通过 配置集群: archive_mode: off 来关闭 WAL 归档,移除 node_crontab 来停止定期备份任务。
实现
默认情况下,Pigsty提供了两种预置 备份策略:默认使用本地文件系统备份仓库,在这种情况下每天进行一次全量备份,确保用户任何时候都能回滚至一天内的任意时间点。备选策略使用专用的 MinIO 集群或S3存储备份,每周一全备,每天一增备,默认保留两周的备份与WAL归档。
Pigsty 使用 pgBackRest 管理备份,接收 WAL 归档,执行 PITR。备份仓库可以进行灵活配置(pgbackrest_repo):默认使用主库本地文件系统(local),但也可以使用其他磁盘路径,或使用自带的可选 MinIO 服务(minio)与云上 S3 服务。
pgbackrest_enabled: true # 在 pgsql 主机上启用 pgBackRest 吗?
pgbackrest_clean: true # 初始化时删除 pg 备份数据?
pgbackrest_log_dir: /pg/log/pgbackrest # pgbackrest 日志目录,默认为 `/pg/log/pgbackrest`
pgbackrest_method: local # pgbackrest 仓库方法:local, minio, [用户定义...]
pgbackrest_repo: # pgbackrest 仓库:https://pgbackrest.org/configuration.html#section-repository
local: # 默认使用本地 posix 文件系统的 pgbackrest 仓库
path: /pg/backup # 本地备份目录,默认为 `/pg/backup`
retention_full_type: count # 按计数保留完整备份
retention_full: 2 # 使用本地文件系统仓库时,最多保留 3 个完整备份,至少保留 2 个
minio: # pgbackrest 的可选 minio 仓库
type: s3 # minio 是与 s3 兼容的,所以使用 s3
s3_endpoint: sss.pigsty # minio 端点域名,默认为 `sss.pigsty`
s3_region: us-east-1 # minio 区域,默认为 us-east-1,对 minio 无效
s3_bucket: pgsql # minio 桶名称,默认为 `pgsql`
s3_key: pgbackrest # pgbackrest 的 minio 用户访问密钥
s3_key_secret: S3User.Backup # pgbackrest 的 minio 用户秘密密钥
s3_uri_style: path # 对 minio 使用路径风格的 uri,而不是主机风格
path: /pgbackrest # minio 备份路径,默认为 `/pgbackrest`
storage_port: 9000 # minio 端口,默认为 9000
storage_ca_file: /etc/pki/ca.crt # minio ca 文件路径,默认为 `/etc/pki/ca.crt`
bundle: y # 将小文件打包成一个文件
cipher_type: aes-256-cbc # 为远程备份仓库启用 AES 加密
cipher_pass: pgBackRest # AES 加密密码,默认为 'pgBackRest'
retention_full_type: time # 在 minio 仓库上按时间保留完整备份
retention_full: 14 # 保留过去 14 天的完整备份
# 您还可以添加其他的可选备份仓库,例如 S3,用于异地容灾
Pigsty 参数 pgbackrest_repo 中的目标仓库会被转换为 /etc/pgbackrest/pgbackrest.conf 配置文件中的仓库定义。
例如,如果您定义了一个美西区的 S3 仓库用于存储冷备份,可以使用下面的参考配置。
s3: # ------> /etc/pgbackrest/pgbackrest.conf
repo1-type: s3 # ----> repo1-type=s3
repo1-s3-region: us-west-1 # ----> repo1-s3-region=us-west-1
repo1-s3-endpoint: s3-us-west-1.amazonaws.com # ----> repo1-s3-endpoint=s3-us-west-1.amazonaws.com
repo1-s3-key: '<your_access_key>' # ----> repo1-s3-key=<your_access_key>
repo1-s3-key-secret: '<your_secret_key>' # ----> repo1-s3-key-secret=<your_secret_key>
repo1-s3-bucket: pgsql # ----> repo1-s3-bucket=pgsql
repo1-s3-uri-style: host # ----> repo1-s3-uri-style=host
repo1-path: /pgbackrest # ----> repo1-path=/pgbackrest
repo1-bundle: y # ----> repo1-bundle=y
repo1-cipher-type: aes-256-cbc # ----> repo1-cipher-type=aes-256-cbc
repo1-cipher-pass: pgBackRest # ----> repo1-cipher-pass=pgBackRest
repo1-retention-full-type: time # ----> repo1-retention-full-type=time
repo1-retention-full: 90 # ----> repo1-retention-full=90
恢复
您可以直接使用以下封装命令可以用于 PostgreSQL 数据库集群的 时间点恢复。
Pigsty 默认使用增量差分并行恢复,允许您以最快速度恢复到指定时间点。
pg-pitr # 恢复到WAL存档流的结束位置(例如在整个数据中心故障的情况下使用)
pg-pitr -i # 恢复到最近备份完成的时间(不常用)
pg-pitr --time="2022-12-30 14:44:44+08" # 恢复到指定的时间点(在删除数据库或表的情况下使用)
pg-pitr --name="my-restore-point" # 恢复到使用 pg_create_restore_point 创建的命名恢复点
pg-pitr --lsn="0/7C82CB8" -X # 在LSN之前立即恢复
pg-pitr --xid="1234567" -X -P # 在指定的事务ID之前立即恢复,然后将集群直接提升为主库
pg-pitr --backup=latest # 恢复到最新的备份集
pg-pitr --backup=20221108-105325 # 恢复到特定备份集,备份集可以使用 pgbackrest info 列出
pg-pitr # pgbackrest --stanza=pg-meta restore
pg-pitr -i # pgbackrest --stanza=pg-meta --type=immediate restore
pg-pitr -t "2022-12-30 14:44:44+08" # pgbackrest --stanza=pg-meta --type=time --target="2022-12-30 14:44:44+08" restore
pg-pitr -n "my-restore-point" # pgbackrest --stanza=pg-meta --type=name --target=my-restore-point restore
pg-pitr -b 20221108-105325F # pgbackrest --stanza=pg-meta --type=name --set=20221230-120101F restore
pg-pitr -l "0/7C82CB8" -X # pgbackrest --stanza=pg-meta --type=lsn --target="0/7C82CB8" --target-exclusive restore
pg-pitr -x 1234567 -X -P # pgbackrest --stanza=pg-meta --type=xid --target="0/7C82CB8" --target-exclusive --target-action=promote restore
在执行 PITR 时,您可以使用 Pigsty 监控系统观察集群 LSN 位点状态,判断是否成功恢复到指定的时间点,事务点,LSN位点,或其他点位。
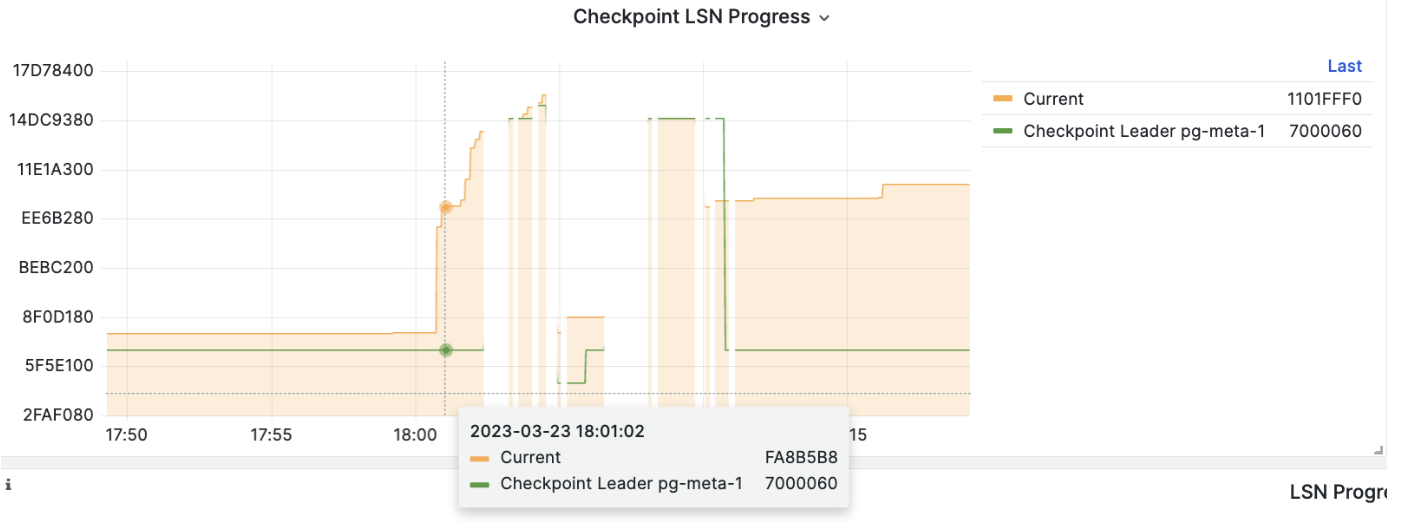
1 - 时间点恢复的工作原理
本文解释 PITR 的工作机制,帮助您建立正确的心智模型:基础备份、WAL 归档、恢复窗口与事务边界
时间点恢复(PITR)的核心原理是:基础备份 + WAL 归档 = 任意时间点恢复能力。
基础备份
基础备份(Base Backup)是数据库在某个时刻的完整物理快照,包含所有数据文件、配置文件和表空间——相当于给数据库拍了一张「全家福」。
基础备份是 PITR 的起点:没有基础备份,就没有恢复的基础;有了基础备份,再配合 WAL 归档,就能恢复到备份之后的任意时间点。
备份类型
pgBackRest 支持三种备份类型:
| 类型 | 说明 | 适用场景 |
|---|
| 全量备份(Full) | 完整复制所有数据文件 | 作为恢复的基准点 |
| 差异备份(Differential) | 仅记录与上次全量备份的差异 | 平衡空间与恢复速度 |
| 增量备份(Incremental) | 仅记录与上次任意备份的差异 | 最省空间,恢复较慢 |
全量备份是独立的,可以单独用于恢复;差异备份和增量备份则依赖于之前的备份链条。
为什么需要定期备份
基础备份的时间点决定了恢复时需要重放多少 WAL 日志:
- 备份越新,需要重放的 WAL 越少,恢复越快
- 备份越旧,需要重放的 WAL 越多,恢复越慢
因此,生产环境通常采用每日备份策略。具体操作请参阅 备份机制 与 备份策略。
WAL 归档
WAL(Write-Ahead Log,预写式日志)是 PostgreSQL 的事务日志。数据库的每一次写操作——INSERT、UPDATE、DELETE、DDL——都会先写入 WAL,然后才修改实际的数据文件。
这就是「预写式」的含义:先写日志,后写数据。
WAL 归档的作用
WAL 归档是将已完成的 WAL 段文件持久化保存到备份仓库的过程,其作用包括:
- 记录变更:捕获基础备份之后发生的所有数据变更
- 连续保护:从备份点到当前时刻,所有变更都被完整记录
- 任意恢复:配合基础备份,可恢复到归档范围内的任意时间点
恢复的本质
PITR 恢复的本质是:
- 还原基础备份——回到备份时刻的状态
- 重放 WAL 归档——逐条应用备份之后的变更
- 停止在目标时间点——达到期望的状态
这就像「录像回放」:基础备份是起点画面,WAL 是录像带,恢复就是从起点开始播放到指定时刻。
自动归档
Pigsty 默认在集群主库上启用 WAL 归档,pgBackRest 会自动完成以下工作:
- 接收并存储 WAL 段文件
- 根据保留策略清理过期的归档文件
- 在恢复时自动获取所需的 WAL 归档
您无需手动管理 WAL 归档,一切都是自动的。
恢复窗口
恢复窗口(Recovery Window)是指您可以恢复到的时间范围,由两个边界决定:
- 左边界:最早可用的基础备份时间点
- 右边界:最新的 WAL 归档时间点(通常接近当前时刻)

影响因素
恢复窗口受以下因素影响:
| 因素 | 影响 |
|---|
| 备份保留数量 | 保留的备份越多,左边界越早 |
| 备份保留时间 | 保留时间越长,左边界越早 |
| WAL 归档保留 | WAL 归档与备份保留策略联动 |
默认配置
Pigsty 提供两种默认配置:
- 本地仓库:保留 2 个全量备份,恢复窗口约 24~48 小时
- MinIO/S3 仓库:保留 14 天备份,恢复窗口约 1~2 周
只要存储空间充足,您可以配置任意长度的恢复窗口。详细配置请参阅 备份策略 与 备份仓库。
事务边界
当您指定「恢复到某个时间点」时,PostgreSQL 实际上是恢复到该时刻已提交事务的状态。
事务状态
在任意时刻,事务有两种状态:
- 已提交(Committed):事务已完成,数据变更永久生效
- 未提交(Uncommitted):事务进行中,数据变更尚未最终确认
恢复时的事务处理
PITR 恢复时:
gantt
title 事务边界与恢复目标
dateFormat X
axisFormat %s
section 事务 A
BEGIN → COMMIT (已提交) :done, a1, 0, 2
section 事务 B
BEGIN → 未提交 :active, b1, 1, 4
section 恢复
恢复目标点 :milestone, m1, 2, 0恢复结果:事务 A 的变更保留,事务 B 的变更回滚。
包含与排除
恢复目标默认是包含(inclusive)的——恢复会包含目标点的事务。
如果您想恢复到某个「坏事务」之前的状态,需要使用 exclusive 参数。例如,事务 ID 250000 执行了误删操作:
xid: 250000:恢复包含该事务(数据仍被删除)xid: 250000, exclusive: true:恢复不包含该事务(数据保留)
详细操作请参阅 恢复操作。
时间线
时间线(Timeline)是 PostgreSQL 用来区分不同「历史分支」的机制。
何时产生新时间线
以下操作会创建新的时间线:
- PITR 恢复后:恢复到过去某点后,从该点开始新的历史
- 从库提升(Promote):从库变主库后,开启新的历史
- 故障切换(Failover):主从切换后,新主库开启新历史
时间线分叉示意
gitGraph
commit id: "初始状态"
commit id: "写入数据"
commit id: "继续写入"
branch Timeline-2
checkout Timeline-2
commit id: "PITR 恢复点1"
commit id: "新写入"
branch Timeline-3
checkout Timeline-3
commit id: "PITR 恢复点2"
commit id: "继续运行"
checkout main
commit id: "原时间线继续"每次 PITR 恢复都会产生新的时间线分支,如同版本控制中的「分支」。
恢复时指定时间线
如果备份仓库中存在多个时间线的 WAL 归档,恢复时需要指定目标时间线:
timeline: latest(默认):恢复到最新的时间线timeline: 1:恢复到指定的时间线编号
对于大多数场景,使用默认的 latest 即可。只有在需要恢复到「历史分支」时,才需要指定具体的时间线编号。
2 - 时间点恢复的实现架构
Pigsty PITR 的实现架构:pgBackRest 工具、备份仓库与执行机制
Pigsty 使用 pgBackRest 作为备份工具,实现 PostgreSQL 的时间点恢复能力。
本文介绍 PITR 的实现架构,帮助您理解备份系统的工作方式。
pgBackRest 简介
pgBackRest 是 PostgreSQL 生态中最成熟、功能最强大的备份恢复工具。Pigsty 选择它作为默认备份方案,主要基于以下优势:
为什么选择 pgBackRest
| 特性 | pgBackRest | pg_basebackup | Barman |
|---|
| 增量备份 | ✅ 原生支持 | ❌ 不支持 | ✅ 支持 |
| 并行备份恢复 | ✅ 多进程并行 | ❌ 单进程 | ✅ 支持 |
| 压缩 | ✅ 多种算法 | ✅ gzip/lz4 | ✅ 支持 |
| 加密 | ✅ AES-256 | ❌ 不支持 | ❌ 不支持 |
| 多仓库 | ✅ 同时备份到多个仓库 | ❌ 不支持 | ❌ 不支持 |
| 对象存储 | ✅ S3/MinIO/Azure/GCS | ❌ 不支持 | ✅ S3 |
| 块级增量 | ✅ 支持 | ❌ 不支持 | ❌ 不支持 |
核心能力
- 增量备份:仅备份变更的数据块,大幅减少备份时间与存储空间
- 并行处理:多进程并行备份和恢复,充分利用系统资源
- 透明加密:AES-256-CBC 加密,保护备份数据安全
- 多仓库支持:同时备份到本地和远程,实现多级容灾
- 自动 WAL 管理:自动归档和清理 WAL 文件,无需人工干预
在 Pigsty 中的集成
Pigsty 对 pgBackRest 进行了开箱即用的集成:
- 默认启用:所有 PostgreSQL 集群自动配置备份
- 自动配置:根据集群名称自动生成 stanza 和仓库配置
- 封装脚本:提供
pg-backup、pg-pitr 等便捷命令 - 监控集成:pgbackrest_exporter 导出备份指标到 Prometheus
核心概念
理解 pgBackRest 的两个核心概念,是掌握备份架构的关键。
Stanza(数据库集群标识)
Stanza 是 pgBackRest 中用于标识一个 PostgreSQL 集群的名称。在 Pigsty 中:
- 每个 PostgreSQL 集群对应一个 stanza
- Stanza 名称 = 集群名称(
pg_cluster) - 例如:集群
pg-meta 的 stanza 就是 pg-meta
Stanza 的作用是在备份仓库中隔离不同集群的数据。一个仓库可以存储多个集群的备份,通过 stanza 加以区分。
备份仓库
├── pg-meta/ # pg-meta 集群的 stanza
│ ├── backup/ # 基础备份
│ └── archive/ # WAL 归档
├── pg-test/ # pg-test 集群的 stanza
│ ├── backup/
│ └── archive/
└── pg-prod/ # pg-prod 集群的 stanza
├── backup/
└── archive/
Repository(备份仓库)
Repository 是存储备份数据和 WAL 归档的位置。Pigsty 支持多种仓库类型:
| 类型 | 说明 | 典型用途 |
|---|
| local | 本地文件系统 | 开发环境、单机部署 |
| minio | MinIO 对象存储 | 生产环境、多集群共享 |
| s3 | AWS S3 及兼容存储 | 云上部署、异地容灾 |
一个集群可以同时配置多个仓库,实现多级备份策略。
备份架构
部署模式
pgBackRest 部署在所有 PostgreSQL 节点上,但实际的备份操作仅在主库执行:
flowchart TB
subgraph cluster["PostgreSQL 集群"]
direction LR
subgraph primary["主库 Primary"]
p1["pgBackRest ✓"]
p2["执行备份 ✓"]
p3["WAL 归档 ✓"]
end
subgraph replica1["从库 1"]
r1["pgBackRest ✓"]
r2["不执行备份"]
r3["不归档"]
end
subgraph replica2["从库 2"]
s1["pgBackRest ✓"]
s2["不执行备份"]
s3["不归档"]
end
end
subgraph repo["备份仓库"]
storage["本地文件系统 / MinIO / S3"]
end
primary -->|备份 & WAL| repo故障切换后的备份
定时备份任务(crontab)在所有节点上配置,但只有主库才会实际执行备份:
- 备份脚本会检查当前节点角色
- 仅主库节点执行备份操作
- 从库节点的备份任务静默跳过
故障切换后:
- 新主库(原从库)自动开始执行备份
- 新主库自动接管 WAL 归档
- 备份连续性不受影响
这种设计确保了高可用环境下备份的无缝切换。
仓库类型
本地文件系统(local)
默认选项,将备份存储在主库本地磁盘:
| 优势 | 劣势 |
|---|
| 配置简单,开箱即用 | 无异地容灾能力 |
| 恢复速度快(本地 I/O) | 受限于本地磁盘空间 |
| 无网络依赖 | 主机故障时备份可能一起丢失 |
适用场景:开发测试环境、单机部署、对容灾要求不高的场景。
对象存储(MinIO/S3)
将备份存储在远程对象存储服务:
| 优势 | 劣势 |
|---|
| 异地容灾,独立于数据库主机 | 恢复速度较慢(网络传输) |
| 几乎无限的存储容量 | 需要额外基础设施 |
| 多集群共享同一仓库 | 依赖网络可用性 |
| 支持加密和版本控制 | 配置相对复杂 |
适用场景:生产环境、关键业务、需要异地容灾的场景。
如何选择
| 场景 | 推荐仓库 |
|---|
| 单机开发环境 | local |
| 生产集群(单机房) | local + minio |
| 生产集群(多机房) | minio / s3 |
| 关键业务 | local + minio(双仓库) |
详细的仓库配置请参阅 备份仓库。
3 - 时间点恢复的策略权衡
PITR 策略设计中的利弊权衡:仓库选择、空间规划与策略推荐
设计 PITR 策略需要在多个维度进行权衡:存储位置、空间消耗、恢复窗口、恢复速度。
本文帮助您理解这些权衡点,做出适合自身场景的决策。
本地 vs 远程
备份仓库的位置选择,是 PITR 策略设计的首要决策。
本地仓库
将备份存储在主库本地磁盘(默认 /pg/backup):
优势:
- ✅ 配置简单:开箱即用,无需额外基础设施
- ✅ 恢复快速:本地 I/O,无网络延迟
- ✅ 无依赖:不依赖网络和外部服务
劣势:
- ❌ 无异地容灾:主机故障时,备份可能一同丢失
- ❌ 空间受限:受本地磁盘容量限制
- ❌ 单点风险:备份与数据位于同一物理位置
远程仓库
将备份存储在 MinIO、S3 或其他对象存储:
优势:
- ✅ 异地容灾:备份独立于数据库主机
- ✅ 空间无限:对象存储容量几乎无限
- ✅ 多集群共享:多个集群可共用同一仓库
- ✅ 安全增强:支持加密、版本控制、防删锁定
劣势:
- ❌ 恢复较慢:需要网络传输,恢复耗时更长
- ❌ 依赖网络:网络故障会影响备份和恢复
- ❌ 额外成本:需要部署和维护对象存储服务
如何选择
| 场景 | 推荐方案 | 理由 |
|---|
| 开发测试 | 本地仓库 | 简单够用,容灾要求低 |
| 单机生产 | 远程仓库 | 主机故障时仍可恢复 |
| 集群生产 | 本地 + 远程 | 兼顾速度与容灾 |
| 关键业务 | 多远程仓库 | 多地容灾,最高保护 |
空间 vs 窗口
恢复窗口与存储空间是一对此消彼长的关系:窗口越长,空间消耗越大。
空间消耗因素
备份存储空间受以下因素影响:
| 因素 | 影响 |
|---|
| 数据库大小 | 基础消耗,决定全量备份大小 |
| 备份保留数量 | 保留越多,空间消耗越大 |
| 数据变更速率 | 变更越多,WAL 归档越大 |
| 备份类型 | 增量备份比全量备份节省空间 |
空间估算
以 100GB 数据库、每日 10GB 变更为例:
每日全量备份策略(保留 2 个备份):

- 全量备份:100GB × 2 = 200GB
- WAL 归档:10GB × 2 = 20GB
- 总计约:220GB(数据库的 2~3 倍)
周全量 + 每日增量策略(保留 2 周):

- 全量备份:100GB × 2 = 200GB
- 增量备份:约 10GB × 12 = 120GB
- WAL 归档:10GB × 14 = 140GB
- 总计约:460GB
空间与窗口的权衡
| 目标 | 策略调整 | 代价 |
|---|
| 更长恢复窗口 | 增加保留数量/时间 | 更多存储空间 |
| 更快恢复速度 | 增加备份频率 | 更多存储空间 |
| 节省存储空间 | 使用增量备份 | 恢复速度略慢 |
| 最省存储空间 | 减少保留数量 | 恢复窗口缩短 |
策略选择
每日全量备份
最简单可靠的策略,适合大多数场景:
- 每天凌晨执行全量备份
- 保留最近 2 个备份
- 恢复窗口:24~48 小时
优点:
- 配置简单,不易出错
- 恢复速度快(无需合并增量)
- 每个备份独立,互不依赖
适用场景:
全量 + 增量备份
空间优化策略,适合大型数据库:
- 每周一凌晨执行全量备份
- 其他工作日执行增量备份
- 保留最近 14 天
优点:
适用场景:
- 数据库 > 500GB
- 使用对象存储
- 需要更长恢复窗口
决策指南
flowchart TD
A{"数据库大小<br/>< 100GB?"} -->|是| B["每日全量备份<br/>(简单可靠)"]
A -->|否| C{"数据库大小<br/>< 500GB?"}
C -->|否| D["全量 + 增量备份<br/>(必须)"]
C -->|是| E{"备份窗口<br/>充足?"}
E -->|是| F["每日全量备份"]
E -->|否| G["全量 + 增量备份"]
推荐配置
开发测试环境
# 本地仓库,每日全量,保留 2 个备份
node_crontab: [ '00 01 * * * postgres /pg/bin/pg-backup full' ]
pgbackrest_method: local
- 恢复窗口:24~48 小时
- 空间消耗:数据库的 2~3 倍
- 特点:配置最简,开箱即用
生产集群
# MinIO 仓库,全量 + 增量,保留 2 周
node_crontab:
- '00 01 * * 1 postgres /pg/bin/pg-backup full'
- '00 01 * * 2,3,4,5,6,7 postgres /pg/bin/pg-backup'
pgbackrest_method: minio
- 恢复窗口:7~14 天
- 空间消耗:取决于变更速率
- 特点:异地容灾,空间充足
关键业务
# 双仓库:本地(快速恢复)+ 远程(异地容灾)
pgbackrest_method: local
# 同时配置 minio 仓库用于异地备份
- 恢复窗口:可配置更长
- 空间消耗:双倍存储
- 特点:双重保护,最高可靠性
详细配置请参阅 备份策略 与 备份仓库。
4 - 时间点恢复的典型场景
PITR 典型应用场景:误删数据、误删表、分支恢复与集群级灾难
本文介绍 PITR 的典型应用场景,帮助您理解「遇到什么问题时应该想到 PITR」。
恢复思路
PITR 恢复并非「按下按钮即完成」的操作,而是一个需要分析、决策、执行、验证的过程。
核心流程
flowchart LR
A["发现问题"] --> B["定位时间点"] --> C["确定目标"] --> D["执行恢复"] --> E["验证结果"]Step 1:发现问题
Step 2:定位时间点
- 查询 PostgreSQL 日志(CSVLOG)
- 查看监控仪表盘(事务 ID、LSN)
- 询问相关人员(操作时间)
Step 3:确定恢复目标
| 已知信息 | 恢复目标类型 |
|---|
| 大概时间 | time(时间点) |
| 精确事务 | xid(事务 ID) |
| WAL 位置 | lsn(日志序列号) |
| 预设检查点 | name(命名恢复点) |
Step 4:执行恢复
- 选择恢复策略:原地回滚或分支恢复
- 执行 PITR 操作
Step 5:验证结果
关键原则
先确定目标,再执行恢复。
不要急于执行恢复操作。花时间定位准确的恢复目标,比匆忙恢复后发现时间点不对要好得多。
详细操作请参阅 恢复操作。
误删数据
场景描述
应用程序缺陷或人为操作失误,导致数据被错误删除或覆盖:
- 开发环境的 SQL 误在生产执行
DELETE 语句缺少 WHERE 条件UPDATE 语句覆盖了错误的字段- 批处理脚本的逻辑错误
症状表现
- 用户反馈数据不见了
- 报表数据突然归零或异常
- 某些记录的字段值被错误修改
处理思路
1. 阻止损害扩大
如果问题仍在持续,先暂停相关应用或脚本。
2. 定位问题事务
从 PostgreSQL 日志中找到问题 SQL:
# 查找包含 DELETE 的最近日志
grep "DELETE" /pg/log/postgresql-*.csv | tail -20
或从监控仪表盘查看事务 ID(TXID)。
3. 选择恢复策略
| 策略 | 适用场景 | 优点 | 缺点 |
|---|
| 原地回滚 | 确定时间点,可接受停机 | 简单直接 | 有停机时间 |
| 分支恢复 | 需要验证,不能停机 | 不影响生产 | 操作较复杂 |
4. 执行恢复
如果知道精确的事务 ID,使用 exclusive 参数恢复到该事务之前:
pg_pitr: { xid: "250000", exclusive: true }
如果只知道大概时间:
pg_pitr: { time: "2025-01-15 14:30:00+08" }
误删表或库
场景描述
执行了 DROP TABLE 或 DROP DATABASE:
- 清理测试数据时误删生产表
- 脚本中的库名或表名写错
- 权限控制不当,普通用户执行了危险操作
与误删数据的区别
误删表或库的影响通常更大,但处理思路类似。关键区别在于:
- 误删数据:可能只影响部分记录
- 误删表或库:整个对象消失,影响范围更大
为什么推荐分支恢复
对于误删表或库,强烈推荐分支恢复而非原地回滚:
- 风险隔离:不影响生产系统运行
- 精确恢复:可以只导出需要的表
- 验证充分:有时间确认恢复结果正确
- 灵活处理:可选择性地合并数据
处理流程
sequenceDiagram
participant O as 原集群
participant B as 分支集群
O->>B: 1. 创建分支集群
Note over B: 2. PITR 到误删之前
Note over B: 验证数据正确
B->>O: 3. 导出误删的表
Note over O: 导入数据
Note over B: 4. 验证完成后销毁分支
分支恢复
分支恢复是云厂商 RDS 的标准实践,也是 Pigsty 推荐的恢复方式。
什么是分支恢复
分支恢复并非在原集群上「回滚」,而是:
- 使用同一备份仓库创建新集群
- 新集群 PITR 到目标时间点
- 形成原集群的「历史分支」
gitGraph
commit id: "正常运行"
commit id: "数据写入"
commit id: "恢复点" type: HIGHLIGHT
branch pg-meta-restore
checkout pg-meta-restore
commit id: "PITR 恢复到此"
commit id: "分支集群运行"
checkout main
commit id: "原集群继续运行"
commit id: "不受影响"操作示例
在配置中定义分支集群,使用原集群的备份:
pg-meta-restore:
hosts: { 10.10.10.11: { pg_seq: 1, pg_role: primary } }
vars:
pg_cluster: pg-meta-restore
pg_pitr:
cluster: pg-meta # 使用 pg-meta 的备份
time: "2025-01-15 14:00:00+08"
然后执行 PITR:
./pgsql-pitr.yml -l pg-meta-restore
恢复后的选择
分支集群恢复完成后,有两条路可走:
选项 A:导出数据,合并回原集群
# 从分支集群导出需要的表
pg_dump -h pg-meta-restore -t important_table > data.sql
# 导入到原集群
psql -h pg-meta -f data.sql
适用于:只需恢复部分数据,原集群仍在正常服务。
选项 B:直接切流量到分支集群
修改应用配置或负载均衡,将流量切到分支集群。
适用于:需要完整回滚,或原集群已不可用。
优势
- ✅ 不影响生产:原集群继续运行
- ✅ 可以验证:确认恢复结果正确后再操作
- ✅ 可以后悔:发现恢复点不对,可重新创建分支
- ✅ 灵活处理:可选择导出部分数据或整体切换
集群级灾难
场景描述
这是最极端的场景——整个集群不可用:
- 主机硬件故障(磁盘损坏、主板故障)
- 机房级灾难(断电、火灾、自然灾害)
- 主从全部故障
- 数据被恶意加密(勒索软件)
PITR 的「终极兜底」
当 高可用方案 无法应对时,PITR 是最后的保障:
| 场景 | 高可用方案 | PITR 方案 |
|---|
| 单节点故障 | ✅ 自动切换 | ✅ 可恢复 |
| 主从都故障 | ❌ 无法切换 | ✅ 可恢复 |
| 机房灾难 | ❌ 全军覆没 | ✅ 可恢复(需远程仓库) |
| 数据被删 | ❌ 同步删除 | ✅ 可恢复 |
前提条件
备份必须存储在远程仓库(MinIO/S3)。
如果备份存储在本地磁盘,主机故障时备份也会一同丢失。这就是生产环境需要使用远程仓库的原因:
pgbackrest_method: minio # 使用远程仓库
恢复流程
- 准备新主机:提供新的服务器资源
- 配置集群:使用相同的集群名和仓库配置
- 执行 PITR:从远程仓库恢复
- 验证数据:确认恢复结果
- 恢复服务:切换流量到新集群
# 恢复到 WAL 归档的最新点
./pgsql-pitr.yml -l pg-meta
为什么需要远程仓库
此场景说明了为何关键业务必须使用远程仓库:
- 本地仓库:主机故障 = 数据 + 备份同时丢失 = 永久丢失
- 远程仓库:主机故障 = 仅丢数据,备份仍在 = 可以恢复
详细的仓库配置请参阅 备份仓库。